Use Wozber and land your dream job
Create CV
No registration required
Decoding language, but your CV's translation seems muddled? Unravel the nuances with this NLP Engineer CV example, created with Wozber free CV builder. Learn how to blend your linguistic talents with job requirements, so your career trajectory is as clear and meaningful as the sentences you craft!

NLP engineering work sits at the intersection of research and production. Hiring teams want to see that you can move beyond experiments, choose the right architecture for tasks like classification, named entity recognition, or sentiment analysis, and turn text models into systems that run reliably at scale. Your CV should make that practical range obvious, from model design to optimisation and cross-functional delivery.
A tailored CV changes how quickly your technical depth becomes legible. When the language mirrors the posting, an ATS can connect your background in Python, PyTorch, TensorFlow, model evaluation, and large-scale text pipelines to the role instead of treating your experience as generic machine learning. Wozber's free CV builder helps structure that alignment in an ATS-friendly CV format, so reviewers can see faster whether you have the NLP expertise, production judgment, and collaboration style the job calls for.
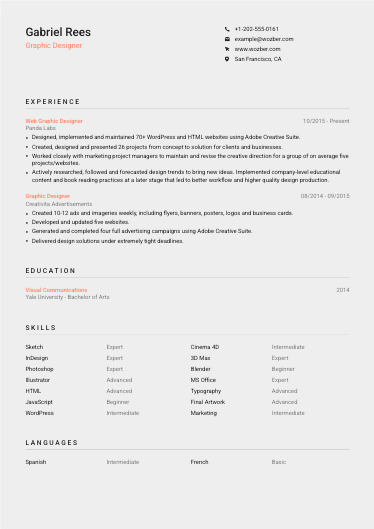
Before anyone gets to transformers, evaluation metrics, or pipeline design, they need to know who you are, how to reach you, and whether you match any practical requirements attached to the opening. Keep this section lean, accurate, and directly aligned with the role.
Use your full name as the main header in a clean, easy-to-scan format. It should be the most visible text on the page, without distracting styling. For technical hiring, clarity matters more than design flourishes.
Place "NLP Engineer" directly beneath your name if that is your current or target title. Matching the posted title helps frame your background correctly from the first line, especially when your past titles vary between NLP Engineer, Machine Learning Engineer, or NLP Specialist.
List a phone number and a professional email address you actively monitor. If you include a website, GitHub, LinkedIn, or technical portfolio, make sure it supports your CV with relevant material such as model work, publications, production projects, or applied NLP case studies.
If the job requires you to be in a specific city or open to relocation, state that clearly. In the example, "San Francisco, California" immediately supports a stated location requirement. For other NLP roles, only include location detail when it helps remove a likely hiring question.
Any public profile linked here should reinforce the same story your CV tells. If your LinkedIn says "ML Engineer" while your CV emphasizes NLP production work, update it so your work in deep learning, text systems, and model deployment reads as one coherent profile.
This header does not need personality language or extra detail. It needs to confirm identity, role direction, and any logistical requirement that affects whether your NLP application moves forward.





This is the section where NLP candidates separate themselves. Hiring teams are looking for more than familiarity with language models. They want to see what kinds of text problems you solved, how your models performed, what scale you worked at, and whether you improved accuracy, latency, throughput, or downstream product outcomes.
Pull out the core work the role emphasizes, then map your experience to it. If the job calls for scalable NLP algorithms, large-volume text processing, model optimisation, and collaboration with data scientists or domain experts, your bullets should answer those points directly. In the example, the experience section mirrors the posting with work on scalable NLP systems, named entity recognition, text classification, and mentoring.
List your most recent position first, then work backward. For each role, include title, company, and dates. That structure lets reviewers quickly connect your current level, years of industry experience, and progression from specialist work into broader ownership or leadership.
Replace generic responsibility lines with concrete accomplishments. A useful NLP bullet often shows the task, the technical approach, and the result. "Developed a named entity recognition solution that reduced false positives by 30%" tells far more than "Worked on NER models." The example CV does this well by tying specific NLP tasks to measurable gains.
Use numbers that reflect how your work was judged. That can include model accuracy, F1 improvement, false positive reduction, latency, processing speed, daily document volume, inference efficiency, or customer-facing response time. Metrics like "boosted processing speed by 40% while maintaining 95% accuracy" are especially effective because they show engineering tradeoffs, not just isolated model quality.
Choose experience that strengthens your case for this kind of role. Production NLP pipelines, deep learning frameworks, text analytics, model evaluation, experimentation, collaboration with product or domain teams, and mentoring are all relevant here. Leave out unrelated accomplishments unless they directly support your ability to ship and improve language-based systems.
Your experience section should make it easy to picture you building, tuning, and delivering NLP systems in a real environment. When the bullets show task type, technical method, scale, and outcome, your background becomes much easier to trust.
For NLP engineering, education still carries weight because the work often draws on machine learning theory, deep learning, statistics, and strong software fundamentals. Degrees help establish that base, especially when the posting asks for computer science, electrical engineering, or a related field.
List your highest completed degree first when it strengthens your case. If you hold a Master's or PhD in Computer Science or a related field, place it prominently, especially when the employer says an advanced degree is preferred. The example CV uses this to reinforce senior technical depth.
Use a consistent structure with degree, field, school, and graduation year. Recruiters and hiring managers should be able to confirm your academic background in seconds without digging through extra wording.
When the posting names Computer Science, Electrical Engineering, or related disciplines, make that match easy to see. If your degree title differs slightly but the coursework was relevant, the field line should still clarify the connection to NLP engineering, machine learning, or computational methods.
If you are early in your career, include coursework, thesis work, or major projects related to NLP, machine learning, deep learning, information retrieval, or large-scale data processing. For experienced candidates, this usually matters less than production results unless your academic work is directly relevant to the target role.
Honors, research labs, teaching assistant work, or competitive technical programs can be worth listing if they reinforce your depth in the field. Keep these additions selective and connected to the kind of analytical or engineering work the role requires.
This section does not need a long narrative. It should quickly show that your formal training supports the level of NLP, machine learning, and engineering work expected in the role.
Certifications are usually secondary to shipped work in NLP engineering, but they can still help when they reinforce core tools, methods, or ongoing specialization. The key is relevance, not volume.
Look for certifications that strengthen the same areas the job emphasizes, such as machine learning, deep learning, NLP, or production AI. In the example, a machine learning credential supports the posting's emphasis on NLP and deep learning capability.
List certifications that add something specific to your profile. Two relevant credentials are stronger than a long list of lightweight courses. Focus on programs tied to recognized platforms, institutions, or directly applicable technical skills.
Show the issue date and, if relevant, whether the certification is still active. In a fast-moving field shaped by evolving architectures and tooling, recent learning can strengthen your case, particularly if your degree is older or your work history spans adjacent ML roles.
NLP changes quickly, from embedding methods to transformer-based workflows to model optimisation practices. Well-chosen certifications can show that you keep your knowledge current and invest in sharpening applied skills beyond formal education.
Treat certifications as supporting material, not the centerpiece. They work best when they reinforce your actual NLP engineering background and show continued development in the methods the job depends on.
The skills section should read like a tight inventory of the technical stack and working strengths you actually use in NLP projects. For this role family, that usually means programming, deep learning frameworks, NLP task expertise, model optimisation, and collaboration across product, research, or domain teams.
Start with the tools, frameworks, and capabilities named in the job ad, provided you genuinely use them. Here, that means surfacing Python, TensorFlow, PyTorch, deep learning, and NLP task areas such as sentiment analysis, named entity recognition, and text classification. This improves both recruiter comprehension and ATS matching.
Do not turn this section into a master inventory of every tool you have touched. Prioritise the skills most likely to matter in the target role, such as model development, large-scale text processing, algorithm design, evaluation, and production optimisation. The example keeps a strong focus on directly relevant NLP and ML capabilities.
Group or order skills in a way that helps reviewers quickly understand your profile. Hard skills should lead. Frameworks, programming, NLP specialties, and model optimisation usually belong near the top, while collaboration and mentorship can follow to support your ability to work across teams and guide junior engineers.
A well-ordered skills section helps hiring teams quickly connect your background to the tools and task areas in the posting. Keep it specific, truthful, and centered on the kind of NLP work you want to keep doing.
Language fluency can matter in NLP roles for two very different reasons: workplace communication and the actual text domains your models support. Keep this section straightforward and tie it to the demands of the job where appropriate.
If the posting requires strong English for customer interactions, list your English proficiency clearly. Use a plain label such as Native, Fluent, or Professional. That removes ambiguity for roles involving client-facing collaboration, annotation guidance, or domain expert discussions.
Order languages by relevance to the position. English will usually lead when it is the main working language. Additional languages can follow if they support multilingual product work, international datasets, or cross-regional collaboration.
Additional languages are worth listing if they connect to the markets, corpora, or customer workflows you may support. They can be a useful differentiator for multilingual NLP environments, but they are not a substitute for core modeling and engineering experience.
Be precise about your level. Overstating language ability can create problems quickly in interviews or customer-facing settings. Choose labels that accurately reflect how well you can communicate, review text, or work in that language.
If your work has involved multilingual classification, language-specific preprocessing, localization, or cross-lingual use cases, language skills can support that story. If not, keep this section brief and factual rather than trying to make it carry more weight than it should.
For an NLP Engineer, this section works best when it clarifies communication capability or supports a multilingual product context. Either way, keep the claims clear and easy to trust.
Your summary should quickly place you in the NLP landscape. In a few lines, it should tell the reader your level, your technical focus, and the kind of outcomes you have delivered with language models or text systems.
Before writing, identify the recurring priorities in the job ad. For this position, those include scalable NLP algorithms, deep learning, model optimisation, cross-functional collaboration, and mentorship. Your summary should reflect that mix rather than reading like a generic machine learning profile.
Start with a direct line such as "NLP Engineer with 6+ years of experience" or whatever accurately matches your background. That first phrase should immediately establish your domain and seniority.
Use the next sentence to surface the capabilities that best match the role. For example, you might mention production NLP systems, Python-based deep learning workflows, model optimisation, or work across tasks like text classification and named entity recognition. The example summary does this by combining technical scope with collaboration and mentoring.
Aim for a compact paragraph, not a biography. Two to four sentences is usually enough to position your background, highlight your strongest NLP value, and invite the reader into the experience section for the detail.
A sharp summary helps the reader place you quickly as an NLP engineer who can build, optimise, and collaborate effectively. Keep it specific enough to sound grounded in real work, not generic AI language.
Your CV should now make one thing clear: you are not simply familiar with NLP concepts, you have applied them in ways that improved model quality, system efficiency, or product outcomes. That is the standard hiring teams are trying to confirm.
Use Wozber's free CV builder to shape that experience into an ATS-compliant CV, refine the wording with job-specific terminology, and check alignment with an ATS CV scanner. The final result should make it easy to judge your technical depth, production impact, and readiness for the NLP Engineer role.